
The error “Cannot Pin ‘torch.cuda.longtensor’ Only Dense CPU Tensors Can Be Pinned” occurs when trying to pin a GPU tensor. Convert it to a CPU tensor using .cpu() to resolve the issue.
This article will explore this error, why it happens, and how to fix it to ensure smooth, efficient data handling in your machine-learning tasks.
What are dense CPU Tensor?
Dense CPU tensors are multi-dimensional arrays of data stored in the CPU. They contain all their elements explicitly, making them ideal for fast numerical calculations. These tensors are commonly used in machine learning for efficient processing.
What is Pinned Memory?
Pinned memory is locked on the CPU, allowing faster data transfer to the GPU. It speeds up processes where large datasets must be quickly moved between the CPU and GPU for processing.
Understanding ‘torch.cuda.longtensor’ and Dense CPU Tensors
Scenario 1: Pinning ‘torch.cuda.longtensor’ to CPU Memory
You cannot pin ‘torch.cuda.longtensor’ directly to CPU memory. Only dense CPU tensors can be pinned, which allows faster memory transfers between the CPU and GPU, improving performance.
Scenario 2: Converting ‘torch.cuda.longtensor’ to Dense CPU Tensor
To convert a ‘torch.cuda.longtensor’ to a dense CPU tensor, use the .cpu() method. This moves the tensor from GPU memory to CPU memory, allowing you to work with it on the CPU.
Scenario 3: Utilizing GPU Memory Efficiently
Only necessary tensors are transferred to the GPU to use GPU memory efficiently. Manage memory with proper tensor allocation and avoid excessive transfers between CPU and GPU to maintain performance.
Scenario 4: Updating PyTorch Versions
Updating PyTorch versions ensures you benefit from bug fixes, new features, and performance improvements. Always check compatibility with your current code to avoid issues after upgrading to a newer version.
What is ‘torch.cuda.longtensor’?
1. Definition and Purpose
A tensor is a multi-dimensional array used in PyTorch for mathematical operations. ‘torch.cuda.longtensor’ specifically stores large integer values on the GPU for efficient deep learning calculations.
2. Differences Between Dense CPU Tensors and GPU Tensors
Dense CPU tensors are stored in CPU memory and hold explicit values. GPU tensors, like ‘torch.cuda.longtensor,’ are stored on the GPU, offering faster computation for deep learning tasks.
Pinning in PyTorch
1. Understanding Tensor Pinning
Tensor pinning locks the memory location of a tensor, preventing it from being swapped out. This allows faster access and data transfer between the CPU and GPU, enhancing computational efficiency.
2. Why ‘torch.cuda.longtensor’ Cannot Be Pinned
‘torch.cuda.longtensor’ cannot be pinned because it is already stored on the GPU, which has its memory management. Only CPU-based tensors can be pinned for efficient transfer between CPU and GPU.
What is Pinned Memory in PyTorch?
Pinned memory, also known as page-locked memory, is allocated in system RAM and cannot be swapped out. This allows for faster data transfer between CPU and GPU.
1. How Does Pinned Memory Improve Performance?
When using pinned memory, data transfer between CPU and GPU happens via direct memory access (DMA), avoiding unnecessary system memory paging. This leads to:
- Faster training and inference speeds
- Reduced CPU-GPU transfer bottlenecks
- Optimized memory handling in deep learning workloads
Peculiarities of CPU and GPU Tensors
1. Exploring Dense CPU Tensors
Dense CPU tensors are multi-dimensional arrays stored in CPU memory. They are fully populated, meaning every element has a value, which allows fast processing for many tasks, especially on the CPU.
2. Limitations of Pinning GPU Tensors
GPU tensors cannot be pinned because the GPU memory system manages them. Pinning is limited to CPU tensors, which can be moved more efficiently between the CPU and GPU for faster data transfer.
3. Implications for Machine Learning Tasks
Pinning CPU tensors allows faster data transfers during machine learning tasks, improving performance. However, GPU tensors cannot be pinned, so developers must handle memory transfers carefully to optimize machine-learning models.
Alternatives and Workarounds
1. Using CPU Tensors for Pinning
CPU tensors can be pinned to improve data transfer speed between CPU and GPU. This is especially useful for deep learning tasks where quick memory access is essential for efficiency.
2. Modifying the Code to Accommodate GPU Constraints
To handle GPU memory limitations, adjust your code using CPU tensors for pinning and only transferring necessary data to the GPU, optimizing memory usage and performance.
Best Practices in Tensor Handling
1. Optimizing Tensor Operations for Performance
For better performance, minimize unnecessary tensor operations and use GPU-optimized functions. Also, batch processing should be considered to reduce overhead and speed up computation.
2. Ensuring Compatibility Across Different Hardware Configurations
Ensure your code handles various hardware configurations by checking GPU memory, using conditional statements for tensor placement, and adapting data transfers for different devices.
When Speed Bumps Your Code?
1. Pinning Memory for Seamless Data Transfer
Pinning memory ensures faster data transfer between CPU and GPU, reducing delays. Use it when moving large datasets to the GPU for quicker computations in deep learning tasks.
2. Supported Tensors: Not All Heroes Wear Capes
Not all tensors can be pinned, especially GPU tensors. Focus on using CPU tensors for pinning to improve memory access and transfer speed, ensuring smoother operations.
Why the Error Occurs?
1. Misplaced pin_memory Enthusiasm
Overusing pin_memory can lead to errors when working with GPU tensors. Applying it to CPU tensors ensures memory management stays efficient and error-free.
2. Dataloader’s Overeager Pinning
Dataloader’s automatic pinning might try to pin GPU tensors, causing errors. Ensure pin_memory is only set for CPU tensors, and adjust the dataloader settings to avoid conflicts and improve performance.
How to Troubleshoot and Fix the Issue
To fix pinning issues, check if you’re trying to pin a GPU tensor. Convert it to a CPU tensor if needed. Also, ensure your PyTorch version supports pinning and that your hardware setup is compatible.
How Does pin_memory work In Dataloader?
pin_memory in DataLoader speeds up data transfer from CPU to GPU by pinning CPU tensors in memory. This helps reduce delays when moving large datasets for deep learning, improving overall training speed.
Using Trainer with LayoutXLM for classification
When using LayoutXLM for classification tasks, ensure your model and data are properly loaded onto the GPU. Use pin_memory=True for faster data transfer, but avoid pinning GPU tensors, which could lead to errors.
Runtimeerror: Pin Memory Thread Exited Unexpectedly
This error happens when the memory pinning thread unexpectedly stops. It’s often due to trying to pin unsupported tensors. Check your code for incorrect tensor types and ensure pin_memory is applied to CPU tensors only.
Pytorch Not Using All GPU Memory
If PyTorch isn’t using all GPU memory, try adjusting the batch size or clearing memory with torch.cuda.empty_cache(). Additionally, ensure your code is optimized for GPU utilization and check for memory bottlenecks.
Huggingface Trainer Use Only One Gpu
Huggingface Trainer may use only one GPU due to default settings or hardware constraints. To utilize multiple GPUs, adjust the configuration to enable distributed training or set up proper multi-GPU support using DataParallel or DistributedDataParallel.
Should I turn off `pin_memory` when I loaded the image to the GPU in `__getitem__`?
Yes, if the image is already on the GPU in __getitem__, turning off pin_memory can avoid redundant memory operations. Pinning is useful for CPU-to-GPU transfers, not when the tensor is already on the GPU.
GPU utilization 0 PyTorch
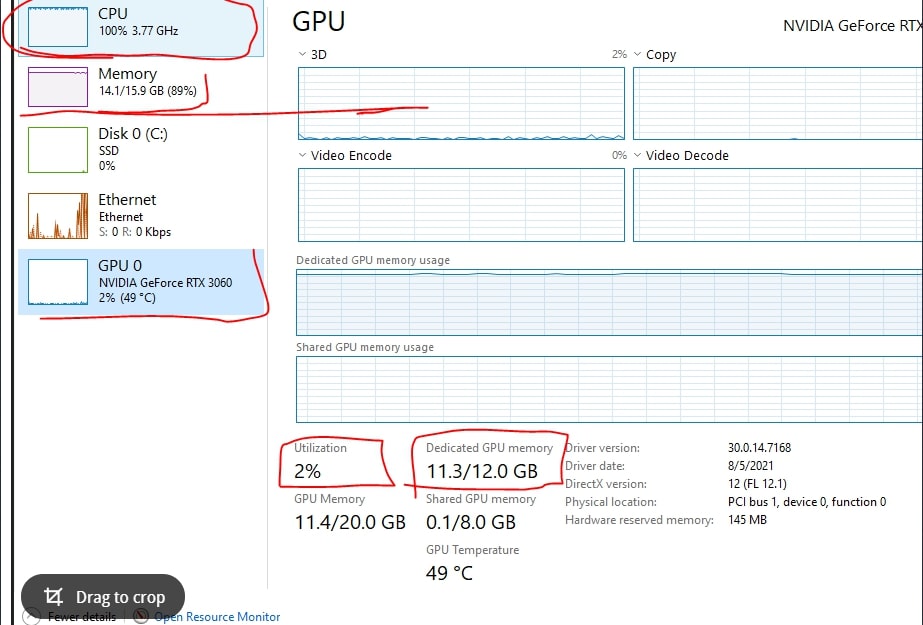
Zero GPU utilization in PyTorch often means the model isn’t fully utilized. Check your data pipeline and batch size, and ensure your model is properly transferred to the GPU. Monitor using nvidia-smi for insights.
When to set pin_memory to true?
Set pin_memory=True in DataLoader when transferring large datasets from CPU to GPU. This allows faster data transfer, improving training performance, especially for models requiring frequent training data loading.
Pytorch pin_memory out of memory
Out-of-memory errors with pin_memory usually occur when there’s insufficient CPU memory. Try reducing the batch size, freeing up unused memory, or avoiding unnecessary pinning of large tensors that don’t need to be transferred to the GPU.
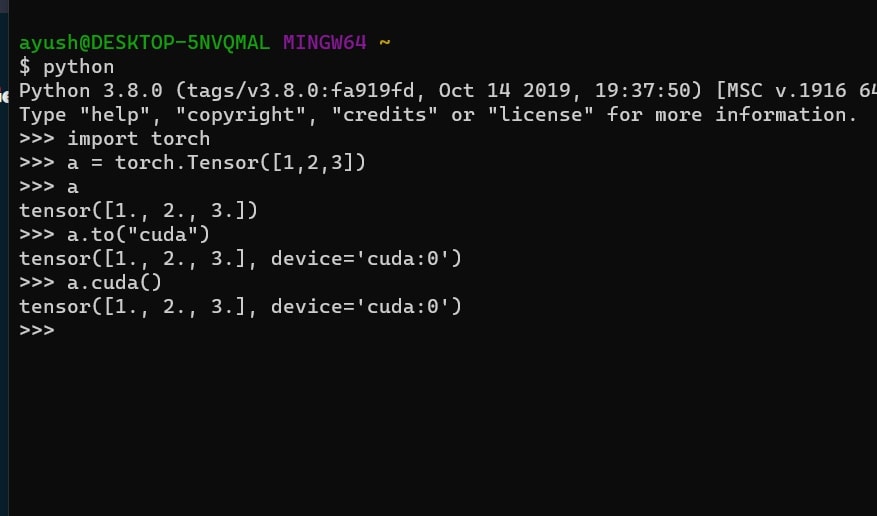
Can’t send PyTorch tensor to Cuda
This error occurs when moving a tensor to a CUDA device without compatibility. Ensure the tensor is on the CPU first and use .to(‘cuda’) to move it. Also, check for device availability.
Differences between `torch.Tensor` and `torch.cuda.Tensor`
torch.Tensor is a general tensor type stored on the CPU, while torch.cuda.Tensor is a tensor stored on the GPU. Operations on torch.cuda.Tensor are faster for large-scale deep learning tasks, utilizing GPU acceleration.
Torch.Tensor — PyTorch 2.3 documentation
torch.Tensor is the core data structure in PyTorch, representing multi-dimensional arrays. The 2.3 documentation provides detailed guidance on tensor creation, manipulation, and operations for CPU and GPU tensors, enabling efficient model building.
Optimize PyTorch Performance for Speed and Memory Efficiency (2022)
To optimize PyTorch performance, reduce memory usage by adjusting batch sizes, using mixed precision, and ensuring tensors are properly transferred between CPU and GPU. Profiling tools like torches.utils. And bottlenecks can help identify bottlenecks.
RuntimeError Caught RuntimeError in pin memory thread for device 0
This error typically happens when there’s an issue with memory allocation or data transfer between CPU and GPU. Ensure your memory is not overloaded and that tensors are correctly managed before pinning them to GPU memory.
How does DataLoader pin_memory=True help with data loading speed?
Setting pin_memory=True in DataLoader speeds up data transfer from CPU to GPU using locked memory. This reduces latency, allowing faster model training by efficiently loading data during each training iteration.
PyTorch expected CPU got CUDA tensor
This error occurs when a function expects a CPU tensor but passes a CUDA tensor. Ensure all tensors are on the correct device before operations using .to(‘cpu’) or .to(‘cuda’).
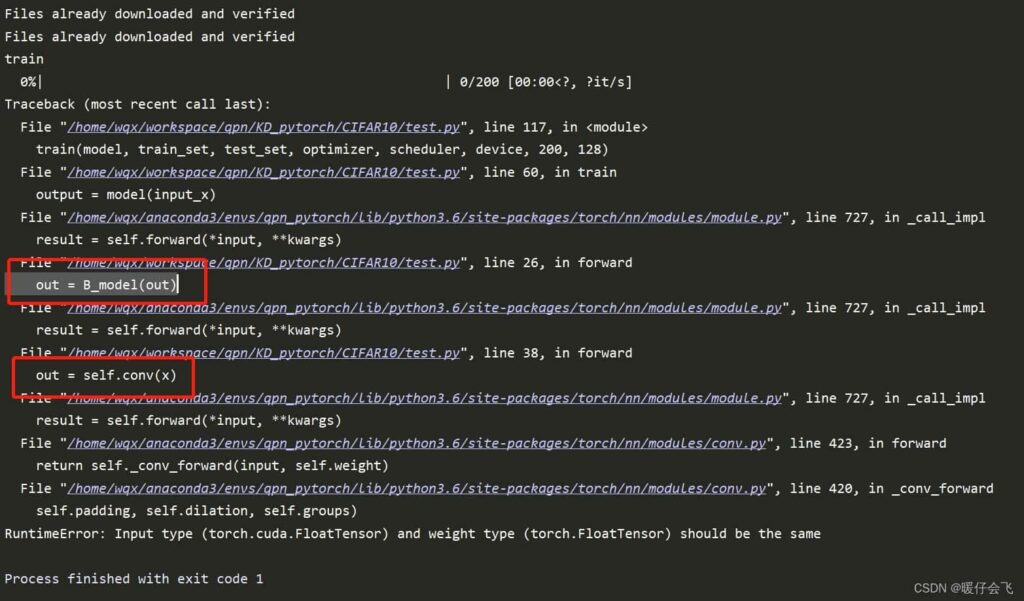
RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
This error happens when input tensors and model weights are on different devices. Ensure both are on CPU or GPU by moving them to the same device with .to(device) to avoid this mismatch.
RuntimeError: _share_filename_: only available on CPU
This error occurs when using _share_filename_ on a CUDA tensor. This function is only supported on CPU tensors. Move the tensor to the CPU using .to(‘cpu’) before using the function.
Tensor pin_memory
pin_memory is a PyTorch feature that locks CPU memory, allowing faster transfer of tensors to GPU. This is useful when training models, as it reduces data loading time and improves performance by minimizing latency during training.
DataLoader pin memory
In DataLoader, setting pin_memory=True allows data to be transferred from CPU to GPU more quickly. This improves training speed, especially when handling large datasets, enabling asynchronous data loading and reducing bottlenecks.
Pin_memory=false
Setting pin_memory=False disables the memory pinning feature in DataLoader. This can be useful when memory usage is a concern or when you’re not utilizing the GPU, but it may slow down data loading during training.
Torch pin_memory
pin_memory() is a PyTorch function that speeds up data transfer from the CPU to the GPU. It locks tensors in system memory, preventing them from being swapped out.
This improves training performance by allowing direct memory access (DMA). However, only dense CPU tensors can be pinned, not GPU tensors.
Pytorch pin memory slow
If pinning memory in PyTorch is slow, it may be due to high memory usage or inefficient data transfer. Try reducing the data size or optimizing your memory usage with better batch management to speed things up.
GPU pin memory
GPU pin memory locks memory in the CPU, making data transfer to the GPU faster. By setting pin_memory=True, PyTorch optimizes data transfer, improving performance when working with large datasets or complex models on the GPU.
When is pinning memory useful for tensors (beyond dataloaders)?
Pinning memory can be helpful when you need to transfer data quickly between CPU and GPU outside of DataLoader. It ensures faster memory access and reduces the overhead during model inference or other GPU operations.
Runtimeerror: caught Runtimeerror in pin memory thread for device 0.
This error often indicates an issue with memory access or transfer. To fix it, ensure your device has enough memory, and check if tensors are being pinned correctly before being transferred between CPU and GPU.
Using pin_memory=False as WSL is detected This may slow down the performance
When using WSL (Windows Subsystem for Linux), setting pin_memory=False may be necessary due to compatibility issues. However, this can slow down performance since memory transfers between CPU and GPU are not optimized.
FAQs
1. What does pin_memory do in PyTorch?
pin_memory helps speed up data transfer between CPU and GPU by locking memory, making it faster for the GPU to access the data.
2. What is torch CUDA using?
torch.cuda allows PyTorch to use the GPU for faster computations by utilizing CUDA (Compute Unified Device Architecture), Nvidia’s parallel computing platform.
3. What is the difference between PyTorch and TorchScript?
PyTorch is a deep learning framework, while TorchScript is an intermediate representation of models allowing optimized deployment outside Python environments.
4. What does Torch Manual_seed do?
torch.manual_seed sets the seed for random number generation in PyTorch, ensuring reproducibility in experiments by initializing the same random numbers each time.
5. What does num workers do in PyTorch?
num_workers specifies the number of subprocesses for data loading in PyTorch, speeding up loading large datasets during training.
6. How can I avoid encountering this error in the future?
To avoid the error, use compatible tensor types and only pin-dense CPU tensors, not CUDA tensors when transferring data to GPU.
7. Can I pin other types of GPU tensors to CPU memory?
No, only dense CPU tensors can be pinned. GPU tensors like torch.cuda.LongTensor cannot be pinned due to different memory structures.
8. Are there any alternatives to pinning ‘torch.cuda.longtensor’?
You can convert torch.cuda.longtensor to a dense CPU tensor before pinning it or use other data transfer methods to optimize memory usage.
9. What does the error message “Cannot Pin ‘torch.cuda.longtensor’ Only Dense CPU Tensors Can Be Pinned” mean?
This error means you tried to pin a GPU tensor to CPU memory, but only dense CPU tensors can be pinned for efficient memory transfer.
10. How can I resolve the “Cannot Pin ‘torch.cuda.longtensor’ Only Dense CPU Tensors Can Be Pinned” error?
To resolve the error, convert torch.cuda.longtensor to a dense CPU tensor using .cpu() and then use pin_memory for efficient memory management.
Conclusion
In conclusion, the “Cannot Pin ‘torch.cuda.longtensor’ Only Dense CPU Tensors Can Be Pinned” error occurs due to memory limitations. Converting the tensor to a dense CPU tensor with .cpu() resolves the issue, improving memory management and overall performance in PyTorch tasks.



